
近几年,诸多互联网公司纷纷搭建数据、技术、AI、组织等各种中台,我们耳边也充斥着五花八门的中台概念。然万变不离其宗,中台化核心目的是降本增效,大多分为两方面,一方面是合并业务之间重复部分,另一方面是为新老业务赋能。
近日,人工智能创业公司循环智能Recurrent的两位联合创始人,CMU计算机博士杨植麟和清华大学计算机博士张宇韬接受了51CTO专访,他们学有所成,学以致用,运用自然语言理解、语音识别,语义理解,数据分析与挖掘等前沿技术将模型算法、人、 数据进行打通,旨在助力企业,打造以服务过程和转化结果为核心的AI销售中台。
学有所成 把技术运用到实际场景
2016年,杨植麟和张宇韬本科时期在同一个实验室,一起研究数据挖掘、处理相关技术,当时就想把所研技术落地到现实场景中,故成立了循环智能,锁定方向为企业服务领域,为销售以及服务行业的沟通过程,提供基于AI技术的优化升级。
当问及为何选择销售场景,他们说,销售离商业模式更近些,销售和客户之间沟通过程中,会产生大量存量非结构化数据,这些本来没有价值的数据,可以通过一系列技术变成有参考价值的解决方案,提升销售效率或转化质量。如果从更大的角度讲,是想用技术去赋能沟通,沟通包含很多种,如企业与客户、企业与企业、C端消费者之间、线下场景等。
两人在技术领域各有所长。杨植麟成为自回归预训练模型 XLNet的第一作者,XLNet 在二十个任务上超过了BERT的表现,并在十八个任务上取得当前最佳效果(state-of-the-art),包括机器问答、自然语言推断、情感分析和文档排序。而张宇韬曾作为核心开发者研发了全球知名的科技大数据分析平台AMiner,产品服务于BATH等科技巨头及国家科技部等政府科研管理机构。
学以致用 打造AI销售中台
时至今日,循环智能完成了由真格基金领投,金沙江创投、靖亚资本、华山资本跟投的A轮融资,此前获得金沙江创投、靖亚资本、华山资本的PreA轮融资,半年融资总额达千万美元,依然专注于销售和客户之间的沟通,但已有了成熟产品组成的的闭环解决方案。
如下图,为循环智能落地案例,AI销售中台于销售端,可以销匹配最佳线索,于客户端,可以做画像分析和挖掘,同时也可以做全量、全渠道的销售质检。

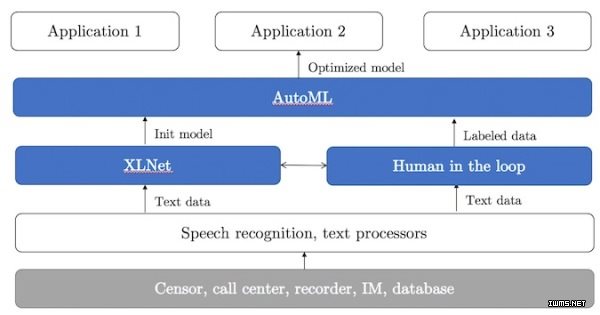
那么,这样一个落地案例背后都需要哪些技术支持呢?自然少不了NLP,自然语言理解、语义、语气、声纹等识别,以及推荐系统等等。
下面介绍一下循环智能自研的语音产品和架构,如下图所示,为自研端到端识别引擎架构图。
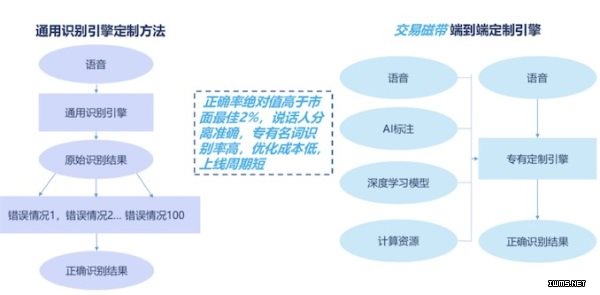
销售与客户之间的沟通语音,可通过识别引擎得到原始识别结果,通过持续试错,最终得到正确结果。
下图为基于上下文的语义理解画像模型。

杨植麟和张宇韬表示,针对基于关键词的质检模型和画像抽取模型在很多质检项下会有大量错报漏的现象, 循环智能的质检模型将种子关键词放入基于tfidf和词向量的语音搜索引擎找到词义和语义的相近提法(Mention),同时通过高频词分析获得与质检项相近的提法,降低漏报率。可以用规则引擎总结表示的提法,将这些提法总结成规则引擎;对于不可以用规则穷尽的提法,利用基于深度学习的文本分类,通过理解上下文语义判断是否命中质检项,降低错报率。
如下图所示,为易扩展的分布式AI架构。

采用语音分析任务的优先级调度机制,确保高优先级任务处理的实时性。采用分布式语音、语义分析引擎,可实现计算资源的弹性扩展,数据处理能力随计算资源线性提升。采用智能化任务调度管理,实现语音识别任务的最优化组装,最大程度利用GPU的计算资源。这样一来,语音识别速度可以提升三倍。
虽然这套自主知识产权的语音识别引擎,是基于原创的Transformer-XL网络架构,可以实现语音至文本的端到端学习。但怎么去压缩硬件成本,特别是在实时语音识别产品压缩硬件成本,还是技术上的挑战。如果能够把成本压缩下来,很多场景都能解锁需求 ,当下也可以做实时但是成本过高,很少有客户能够接受。
AI销售中台核心竞争力:模型算法、人、 数据进行打通
当问及行业定制化的问题,他们这样说,从原始数据到最终的价值整个链条是一个生产线,这个生产线可以根据新行业批量生产标准,之后再导入新行业的数据,及一些对这个行业理解放在系统中,再有标准的人员参与到这个过程中,就可以自动去完成从数据到价值。
本质上是最底层把非结构化的数据去做结构化,实现整个生产线最核心的价值,也就是提供一套生产线,把从非结构化的数据无论是语音还是文本,最终变成一个结构化可以被分析的数据。
如下图,人也是生产流程中非常重要的节点。
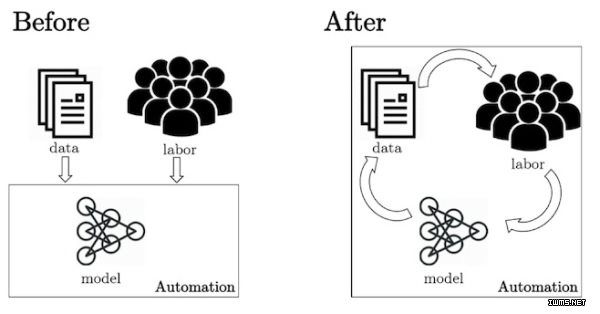
所有知识都是通过人输入,把人整合到标准流程中,人通过调整这个系统去对每个行业去做定制化,把人包含在系统里面,故没有定制化这种说法。
他们还介绍了,在自然语言理解方面,应用了世界领先的自然语言理解算法XLNet,实现了精准自然语言理解,对沟通对话数据进行精确画像挖掘和心声分析,准确率远在传统方法方法之上。基于深度学习的自研推荐系统,从沟通数据中提取丰富的结构化画像,并和XLNet等深度学习方法进行有效融合。在传统行为数据之外又引入了沟通数据,信息密度更大,表现更好。
写在最后:
当问及把AI技术真正落地到现实产品中会遇到哪些难点,杨植麟和张宇韬表示,AI模型主要关注效果层面,如何实现较高准确率或召回率是个问题,在落地时,如何得到工程化系统中更高的考虑性能方面,如成本,服务器,高并发,高吞吐量等也是个问题。如何把非结构化数据结构化,把海量文本数据过滤中间噪音和真正业务结构进行关联,也是个问题。
当问及有哪些竞争对手,杨植麟和张宇韬表示,竞争对手主要来源于三类:可以提供标准化API接口的大厂,传统行业做营销的2B公司以及转型做AI销售中台项目的机器人公司。
《被访者简介》
杨植麟:循环智能联合创始人,产品和AI负责人,曾效力于Facebook AI Research和Google Brain,与多名图灵奖得主合作发表论文,其发明的算法在三十余项AI标准任务上取得世界第一,是XLNet第一作者,获阿里巴巴天池推荐系统竞赛全球第二名、Nvidia先锋研究奖,是连续入选2017-2018NLP一作排行榜的全球三人之一。杨植麟2015年本科毕业于清华大学,2019年博士毕业于卡内基梅隆大学,师从苹果AI负责人Ruslan。
张宇韬:循环智能 联合创始人、CTO。清华大学计算机博士,师从清华大学计算机系副系主任、数据挖掘顶级专家唐杰教授,曾作为核心开发者研发了全球知名的科技大数据分析平台AMiner,产品服务于BATH等科技巨头及国家科技部等政府科研管理机构。

